
What stats should Stever Kerr look at?
Introduction: Steve Kerr – Head Coach of the Golden State Warriors (GSW)
In an interview with The Ringer’s Bill Simmons last year, Steve Kerr said “I look at the opponent’s field goal percentage, our assists, and our turnovers. Those are the three numbers… If we defend and take care of the ball we win. And it’s generally the case, and those three numbers usually tell the story.”
In this post, I identify the stats most important for predicting a GSW win or loss using the machine learning model Random forests.
The Python code I wrote to pull, scrub, and analyze the data is available on Github as a Jupyter notebook
Results: What stats should Stever Kerr look at?
With GSW game logs from the 2015, 2016, and 2017 seasons, I investigated which team stats were most predictive of GSW wins. With the game logs, I constructed a dataset of 16 team and opponent stats for 246 regular season games.
I built a predictive model using Random forests, where the inputs (or predictors) are the team and opponent stats and the output (or response) is either a GSW win or loss. Using cross-validation to evaluate the model’s performance, the accuracy of the model is 89%.
Random forests models provide for a quantification of predictor importance called “feature importance.” The higher the value of “feature importance” the more important it is to the prediction function. We can therefore interpret the stats with the highest “feature importance” as most important for predicting a GSW win or loss.
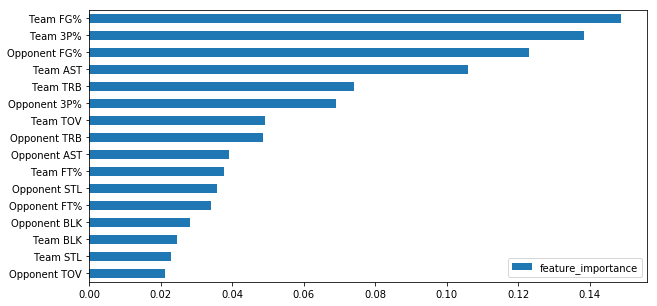
Above is a horizontal bar plot of feature importance for 16 different stats arranged from most important (at the top) to least important (at the bottom). Therefore, the variables most important for predicting a GSW win or loss are Team (GSW) FG% (Field Goal %) and Team (GSW) 3P% (3 Point %) followed by Opponent FG% and Team (GSW) AST (Assists).
According to this analysis, Steve Kerr should priortize looking at his teams’s FG% and 3P% over looking at his team’s turnovers.
Methods: Notes on using Random Forests to perform this analysis
Random forests are a collection of decision trees. To read more about decision trees and random forests, see here.
The main hyper-parameters of the random forests model are the number of trees to grow and the number of features to consider when splitting a node. To read more about these parameters, see here. In this analysis, I chose default values for these hyper-parameters rather than choose the values that yield the best performance as evaluated with cross-validation.
Feature importance is quantified using the concept of “node purity.” To read more about node purity, see here. Features that result in more “pure” nodes are considered more important. To read more about feature importance, see here.